Testi OMA Ettevõtet Minutit
Looge oma konto ja käivitage oma AI chatbot minutite jooksul. Täielikult kohandatav, kodeerimine pole vajalik - alustage klientide kaasamisega kohe!
Valmis minutite jooksul
Kodeerimine pole vajalik
100% turvaline
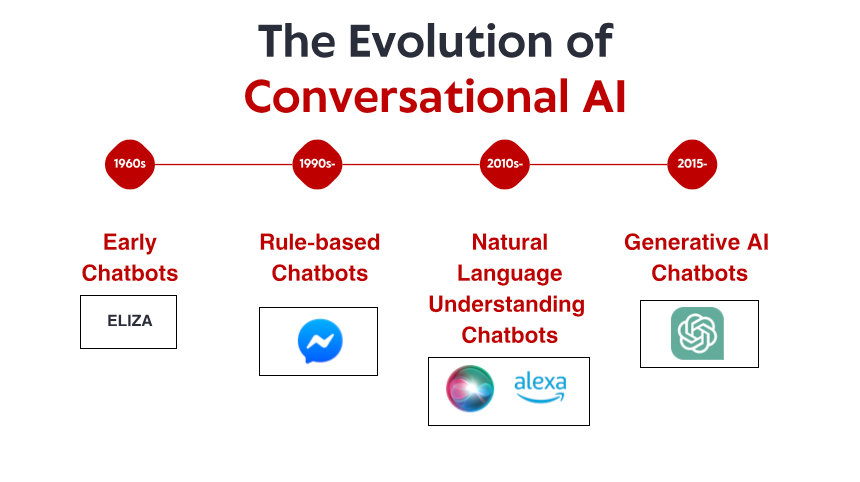
Tagasihoidlik algus: varajased reeglipõhised süsteemid
Vestlusliku tehisintellekti lugu algab 1960. aastatel, ammu enne seda, kui nutitelefonidest ja häälassistentidest said kodutarbed. MIT väikeses laboris lõi arvutiteadlane Joseph Weizenbaum roboti, mida paljud peavad esimeseks vestlusrobotiks: ELIZA. Rogersi psühhoterapeudi simuleerimiseks loodud ELIZA töötas läbi lihtsate mustrite sobitamise ja asendamise reeglite. Kui kasutaja tippis "Ma tunnen end kurvana", võis ELIZA vastata "Miks sa tunned end kurvana?" – luues arusaamise illusiooni, sõnastades väited küsimusteks.
ELIZA ei teinud tähelepanuväärseks mitte selle tehniline keerukus – tänapäeva standardite järgi oli programm uskumatult lihtne. Pigem oli see sügav mõju, mida see kasutajatele avaldas. Hoolimata teadmisest, et nad räägivad arvutiprogrammiga, millest tegelikult aru ei saadud, lõid paljud inimesed ELIZAga emotsionaalse sideme, jagades sügavalt isiklikke mõtteid ja tundeid. See nähtus, mida Weizenbaum ise häirivaks pidas, paljastas midagi olulist inimpsühholoogia ja meie valmisoleku kohta antropomorfiseerida isegi kõige lihtsamaid vestlusliideseid.
1970. ja 1980. aastatel järgisid reeglipõhised vestlusrobotid ELIZA malli järkjärguliste täiustustega. Programmid nagu PARRY (mis simuleerib paranoilist skisofreenikut) ja RACTER (mis "autoriks" raamatu pealkirjaga "Politseiniku habe on pooleldi konstrueeritud") jäid kindlalt reeglipõhise paradigma piiresse – kasutades eelnevalt määratletud mustreid, märksõnade sobitamist ja mallide vastuseid.
Neil varajastel süsteemidel olid tõsised piirangud. Nad ei suutnud tegelikult keelt mõista, interaktsioonidest õppida ega ootamatute sisenditega kohaneda. Nende teadmised piirdusid reeglitega, mille nende programmeerijad olid selgesõnaliselt määratlenud. Kui kasutajad paratamatult nendest piiridest välja kaldusid, purunes intelligentsuse illusioon kiiresti, paljastades aluseks oleva mehaanilise olemuse. Vaatamata neile piirangutele rajasid need teedrajavad süsteemid aluse, millele ehitati kogu tulevane vestluslik tehisintellekt.
ELIZA ei teinud tähelepanuväärseks mitte selle tehniline keerukus – tänapäeva standardite järgi oli programm uskumatult lihtne. Pigem oli see sügav mõju, mida see kasutajatele avaldas. Hoolimata teadmisest, et nad räägivad arvutiprogrammiga, millest tegelikult aru ei saadud, lõid paljud inimesed ELIZAga emotsionaalse sideme, jagades sügavalt isiklikke mõtteid ja tundeid. See nähtus, mida Weizenbaum ise häirivaks pidas, paljastas midagi olulist inimpsühholoogia ja meie valmisoleku kohta antropomorfiseerida isegi kõige lihtsamaid vestlusliideseid.
1970. ja 1980. aastatel järgisid reeglipõhised vestlusrobotid ELIZA malli järkjärguliste täiustustega. Programmid nagu PARRY (mis simuleerib paranoilist skisofreenikut) ja RACTER (mis "autoriks" raamatu pealkirjaga "Politseiniku habe on pooleldi konstrueeritud") jäid kindlalt reeglipõhise paradigma piiresse – kasutades eelnevalt määratletud mustreid, märksõnade sobitamist ja mallide vastuseid.
Neil varajastel süsteemidel olid tõsised piirangud. Nad ei suutnud tegelikult keelt mõista, interaktsioonidest õppida ega ootamatute sisenditega kohaneda. Nende teadmised piirdusid reeglitega, mille nende programmeerijad olid selgesõnaliselt määratlenud. Kui kasutajad paratamatult nendest piiridest välja kaldusid, purunes intelligentsuse illusioon kiiresti, paljastades aluseks oleva mehaanilise olemuse. Vaatamata neile piirangutele rajasid need teedrajavad süsteemid aluse, millele ehitati kogu tulevane vestluslik tehisintellekt.
Teadmiste revolutsioon: ekspertsüsteemid ja struktureeritud teave
1980. ja 1990. aastate alguses tekkisid ekspertsüsteemid – tehisintellekti programmid, mis olid loodud keeruliste probleemide lahendamiseks, jäljendades inimestest ekspertide otsustusvõimet konkreetsetes valdkondades. Kuigi need süsteemid ei olnud peamiselt vestluste jaoks loodud, esindasid need vestlusliku tehisintellekti olulist evolutsioonilist sammu, tuues sisse keerukama teadmiste esitamise.
Ekspertsüsteemid nagu MYCIN (mis diagnoosis bakteriaalseid infektsioone) ja DENDRAL (mis tuvastas keemilisi ühendeid) korraldasid teavet struktureeritud teadmusbaasidesse ja kasutasid järelduste tegemiseks järeldusmootoreid. Vestlusliideste puhul võimaldas see lähenemisviis vestlusrobotitel liikuda lihtsast mustrite sobitamisest edasi millegi arutluskäigu sarnase poole – vähemalt kitsastes valdkondades.
Ettevõtted hakkasid seda tehnoloogiat kasutades rakendama praktilisi rakendusi, näiteks automatiseeritud klienditeenindussüsteeme. Need süsteemid kasutasid tavaliselt otsustuspuid ja menüüpõhiseid interaktsioone vabas vormis vestluste asemel, kuid need esindasid varajasi katseid automatiseerida interaktsioone, mis varem nõudsid inimese sekkumist.
Piirangud jäid märkimisväärseks. Need süsteemid olid haprad ega suutnud ootamatuid sisendeid graatsiliselt käsitleda. Teadmusinseneridelt nõuti tohutuid pingutusi teabe ja reeglite käsitsi kodeerimiseks. Ja mis ehk kõige tähtsam, nad ei suutnud ikka veel päriselt mõista loomulikku keelt selle täielikus keerukuses ja mitmetähenduslikkuses.
Sellegipoolest lõi see ajastu olulisi kontseptsioone, mis hiljem said tänapäevase vestlusliku tehisintellekti jaoks ülioluliseks: struktureeritud teadmiste esitamine, loogiline järeldus ja valdkonna spetsialiseerumine. Lava loodi paradigma muutuseks, kuigi tehnoloogia polnud veel päris olemas.
Ekspertsüsteemid nagu MYCIN (mis diagnoosis bakteriaalseid infektsioone) ja DENDRAL (mis tuvastas keemilisi ühendeid) korraldasid teavet struktureeritud teadmusbaasidesse ja kasutasid järelduste tegemiseks järeldusmootoreid. Vestlusliideste puhul võimaldas see lähenemisviis vestlusrobotitel liikuda lihtsast mustrite sobitamisest edasi millegi arutluskäigu sarnase poole – vähemalt kitsastes valdkondades.
Ettevõtted hakkasid seda tehnoloogiat kasutades rakendama praktilisi rakendusi, näiteks automatiseeritud klienditeenindussüsteeme. Need süsteemid kasutasid tavaliselt otsustuspuid ja menüüpõhiseid interaktsioone vabas vormis vestluste asemel, kuid need esindasid varajasi katseid automatiseerida interaktsioone, mis varem nõudsid inimese sekkumist.
Piirangud jäid märkimisväärseks. Need süsteemid olid haprad ega suutnud ootamatuid sisendeid graatsiliselt käsitleda. Teadmusinseneridelt nõuti tohutuid pingutusi teabe ja reeglite käsitsi kodeerimiseks. Ja mis ehk kõige tähtsam, nad ei suutnud ikka veel päriselt mõista loomulikku keelt selle täielikus keerukuses ja mitmetähenduslikkuses.
Sellegipoolest lõi see ajastu olulisi kontseptsioone, mis hiljem said tänapäevase vestlusliku tehisintellekti jaoks ülioluliseks: struktureeritud teadmiste esitamine, loogiline järeldus ja valdkonna spetsialiseerumine. Lava loodi paradigma muutuseks, kuigi tehnoloogia polnud veel päris olemas.
Looduskeele mõistmine: arvutuslingvistika läbimurre
1990. aastate lõpus ja 2000. aastate alguses hakati üha enam keskenduma loomuliku keele töötlemisele (NLP) ja arvutuslingvistikale. Selle asemel, et proovida iga võimaliku interaktsiooni reegleid käsitsi kodeerida, hakkasid teadlased välja töötama statistilisi meetodeid, mis aitaksid arvutitel mõista inimkeele loomupäraseid mustreid.
Selle nihke võimaldasid mitmed tegurid: arvutusvõimsuse suurenemine, paremad algoritmid ja mis kõige tähtsam, suurte tekstikorpuste kättesaadavus, mida sai analüüsida keeleliste mustrite tuvastamiseks. Süsteemid hakkasid kaasama selliseid tehnikaid nagu:
Kõneosade märgistamine: selle tuvastamine, kas sõnad toimisid nimisõnade, tegusõnade, omadussõnadena jne.
Nimeliste üksuste tuvastamine: pärisnimede (inimesed, organisatsioonid, asukohad) tuvastamine ja klassifitseerimine.
Sentimendianalüüs: teksti emotsionaalse tooni määramine.
Parsimine: lauseehituse analüüsimine sõnade grammatiliste seoste tuvastamiseks.
Üks märkimisväärne läbimurre tuli IBM-i Watsoniga, mis alistas kuulsalt inimvõitlejad viktoriinis "Jeopardy!". 2011. aastal. Kuigi see polnud rangelt võttes vestlussüsteem, demonstreeris Watson enneolematuid võimeid mõista loomuliku keele küsimusi, otsida ulatuslikest teadmistebaasidest ja sõnastada vastuseid – võimed, mis osutusid järgmise põlvkonna vestlusrobotite jaoks hädavajalikuks.
Peagi järgnesid kommertsrakendused. Apple'i Siri turuletoomisel 2011. aastal tuues vestlusliidesed tavatarbijateni. Kuigi Siri oli tänapäeva standardite järgi piiratud, esindas see olulist edasiminekut tehisintellekti abiliste kättesaadavaks tegemisel igapäevakasutajatele. Microsofti Cortana, Google'i Assistant ja Amazoni Alexa järgnesid, igaüks neist edendades tarbijale suunatud vestlusliku tehisintellekti tipptaset.
Vaatamata neile edusammudele oli selle ajastu süsteemidel endiselt raskusi konteksti, terve mõistuse ja tõeliselt loomulike vastuste genereerimisega. Need olid keerukamad kui nende reeglipõhised eelkäijad, kuid jäid keele ja maailma mõistmisel põhimõtteliselt piiratuks.
Selle nihke võimaldasid mitmed tegurid: arvutusvõimsuse suurenemine, paremad algoritmid ja mis kõige tähtsam, suurte tekstikorpuste kättesaadavus, mida sai analüüsida keeleliste mustrite tuvastamiseks. Süsteemid hakkasid kaasama selliseid tehnikaid nagu:
Kõneosade märgistamine: selle tuvastamine, kas sõnad toimisid nimisõnade, tegusõnade, omadussõnadena jne.
Nimeliste üksuste tuvastamine: pärisnimede (inimesed, organisatsioonid, asukohad) tuvastamine ja klassifitseerimine.
Sentimendianalüüs: teksti emotsionaalse tooni määramine.
Parsimine: lauseehituse analüüsimine sõnade grammatiliste seoste tuvastamiseks.
Üks märkimisväärne läbimurre tuli IBM-i Watsoniga, mis alistas kuulsalt inimvõitlejad viktoriinis "Jeopardy!". 2011. aastal. Kuigi see polnud rangelt võttes vestlussüsteem, demonstreeris Watson enneolematuid võimeid mõista loomuliku keele küsimusi, otsida ulatuslikest teadmistebaasidest ja sõnastada vastuseid – võimed, mis osutusid järgmise põlvkonna vestlusrobotite jaoks hädavajalikuks.
Peagi järgnesid kommertsrakendused. Apple'i Siri turuletoomisel 2011. aastal tuues vestlusliidesed tavatarbijateni. Kuigi Siri oli tänapäeva standardite järgi piiratud, esindas see olulist edasiminekut tehisintellekti abiliste kättesaadavaks tegemisel igapäevakasutajatele. Microsofti Cortana, Google'i Assistant ja Amazoni Alexa järgnesid, igaüks neist edendades tarbijale suunatud vestlusliku tehisintellekti tipptaset.
Vaatamata neile edusammudele oli selle ajastu süsteemidel endiselt raskusi konteksti, terve mõistuse ja tõeliselt loomulike vastuste genereerimisega. Need olid keerukamad kui nende reeglipõhised eelkäijad, kuid jäid keele ja maailma mõistmisel põhimõtteliselt piiratuks.
Masinõpe ja andmepõhine lähenemine
2010. aastate keskpaik tähistas vestluspõhise tehisintellekti järjekordset paradigma muutust, kui masinõppe tehnikad laialdaselt kasutusele võeti. Selle asemel, et tugineda käsitsi loodud reeglitele või piiratud statistilistele mudelitele, hakkasid insenerid ehitama süsteeme, mis suutsid mustreid otse andmetest õppida – ja palju.
Sellel ajastul tõusid esile kavatsuste klassifitseerimine ja üksuste eraldamine vestlusarhitektuuri põhikomponentidena. Kui kasutaja esitas päringu, siis süsteem:
klassifitseeris üldise kavatsuse (nt lennu broneerimine, ilma kontrollimine, muusika mängimine)
eraldas asjakohased üksused (nt asukohad, kuupäevad, laulude pealkirjad)
seostas need konkreetsete toimingute või vastustega
Facebooki (nüüd Meta) Messengeri platvormi käivitamine 2016. aastal võimaldas arendajatel luua vestlusroboteid, mis võisid jõuda miljonite kasutajateni, tekitades ärihuvi laine. Paljud ettevõtted kiirustasid vestlusroboteid rakendama, kuigi tulemused olid erinevad. Varased kommertsrakendused valmistasid kasutajatele sageli pettumust piiratud arusaamise ja jäikade vestlusvoogudega.
Sel perioodil arenes ka vestlussüsteemide tehniline arhitektuur. Tüüpiline lähenemisviis hõlmas spetsiaalsete komponentide torujuhet:
Automaatne kõnetuvastus (hääleliideste jaoks)
Loomuliku keele mõistmine
Dialoogide haldamine
Loomuliku keele genereerimine
Tekst kõneks (hääleliideste jaoks)
Iga komponenti sai eraldi optimeerida, mis võimaldas järkjärgulisi täiustusi. Need torujuhtme arhitektuurid kannatasid aga mõnikord vigade leviku all – algstaadiumis tehtud vead levisid kogu süsteemis.
Kuigi masinõpe parandas oluliselt võimekust, oli süsteemidel endiselt raskusi konteksti säilitamisega pikkade vestluste ajal, varjatud teabe mõistmisega ning tõeliselt mitmekesiste ja loomulike vastuste genereerimisega. Järgmine läbimurre nõudis radikaalsemat lähenemisviisi.
Sellel ajastul tõusid esile kavatsuste klassifitseerimine ja üksuste eraldamine vestlusarhitektuuri põhikomponentidena. Kui kasutaja esitas päringu, siis süsteem:
klassifitseeris üldise kavatsuse (nt lennu broneerimine, ilma kontrollimine, muusika mängimine)
eraldas asjakohased üksused (nt asukohad, kuupäevad, laulude pealkirjad)
seostas need konkreetsete toimingute või vastustega
Facebooki (nüüd Meta) Messengeri platvormi käivitamine 2016. aastal võimaldas arendajatel luua vestlusroboteid, mis võisid jõuda miljonite kasutajateni, tekitades ärihuvi laine. Paljud ettevõtted kiirustasid vestlusroboteid rakendama, kuigi tulemused olid erinevad. Varased kommertsrakendused valmistasid kasutajatele sageli pettumust piiratud arusaamise ja jäikade vestlusvoogudega.
Sel perioodil arenes ka vestlussüsteemide tehniline arhitektuur. Tüüpiline lähenemisviis hõlmas spetsiaalsete komponentide torujuhet:
Automaatne kõnetuvastus (hääleliideste jaoks)
Loomuliku keele mõistmine
Dialoogide haldamine
Loomuliku keele genereerimine
Tekst kõneks (hääleliideste jaoks)
Iga komponenti sai eraldi optimeerida, mis võimaldas järkjärgulisi täiustusi. Need torujuhtme arhitektuurid kannatasid aga mõnikord vigade leviku all – algstaadiumis tehtud vead levisid kogu süsteemis.
Kuigi masinõpe parandas oluliselt võimekust, oli süsteemidel endiselt raskusi konteksti säilitamisega pikkade vestluste ajal, varjatud teabe mõistmisega ning tõeliselt mitmekesiste ja loomulike vastuste genereerimisega. Järgmine läbimurre nõudis radikaalsemat lähenemisviisi.
Transformeri revolutsioon: närvikeele mudelid
2017. aasta tähistas tehisintellekti ajaloos pöördepunkti, kui avaldati raamat „Attention Is All You Need“ („Tähelepanu on kõik, mida vajate“), mis tutvustas Transformeri arhitektuuri, mis muutis loomuliku keele töötlemist revolutsiooniliselt. Erinevalt varasematest lähenemisviisidest, mis töötlesid teksti järjestikku, said Transformerid käsitleda tervet lõiku samaaegselt, mis võimaldas neil paremini tabada sõnadevahelisi seoseid olenemata nende kaugusest üksteisest.
See innovatsioon võimaldas arendada üha võimsamaid keelemudeleid. 2018. aastal tutvustas Google BERT-i (Bidirectional Encoder Representations from Transformers), mis parandas oluliselt erinevate keele mõistmise ülesannete jõudlust. 2019. aastal avaldas OpenAI GPT-2, demonstreerides enneolematuid võimeid sidusa ja kontekstipõhise teksti genereerimisel.
Kõige dramaatilisem hüpe toimus 2020. aastal GPT-3-ga, mis skaleerus 175 miljardi parameetrini (võrreldes GPT-2 1,5 miljardiga). See tohutu ulatuse suurenemine koos arhitektuuriliste täiustustega andis kvalitatiivselt erinevaid võimalusi. GPT-3 suutis genereerida märkimisväärselt inimlaadset teksti, mõista konteksti tuhandete sõnade ulatuses ja isegi täita ülesandeid, milleks seda polnud otseselt treenitud. Vestluspõhise tehisintellekti puhul kandusid need edusammud vestlusrobotiteni, mis suutsid:
Säilitada sidusaid vestlusi paljude vestlusvoorude jooksul
Mõista nüansirikkaid päringuid ilma selgesõnalise koolituseta
Genereerida mitmekesiseid, kontekstipõhiseid vastuseid
Kohandada oma tooni ja stiili vastavalt kasutaja vajadustele
Toimetulek ebaselgusega ja vajadusel selgitada
ChatGPT avaldamine 2022. aasta lõpus tõi need võimalused peavoolu, meelitades mõne päeva jooksul pärast selle turuletoomist üle miljoni kasutaja. Ühtäkki oli üldsusel juurdepääs vestluspõhisele tehisintellektile, mis tundus kvalitatiivselt erinev kõigest varasemast – paindlikum, teadlikum ja loomulikum oma suhtluses.
Kiiresti järgnesid ärilised rakendused, kus ettevõtted lisasid suuri keelemudeleid oma klienditeenindusplatvormidesse, sisu loomise tööriistadesse ja tootlikkuse rakendustesse. Kiire kasutuselevõtt peegeldas nii tehnoloogilist hüpet kui ka nende mudelite pakutavat intuitiivset liidest – vestlus on ju inimeste jaoks kõige loomulikum viis suhelda.
See innovatsioon võimaldas arendada üha võimsamaid keelemudeleid. 2018. aastal tutvustas Google BERT-i (Bidirectional Encoder Representations from Transformers), mis parandas oluliselt erinevate keele mõistmise ülesannete jõudlust. 2019. aastal avaldas OpenAI GPT-2, demonstreerides enneolematuid võimeid sidusa ja kontekstipõhise teksti genereerimisel.
Kõige dramaatilisem hüpe toimus 2020. aastal GPT-3-ga, mis skaleerus 175 miljardi parameetrini (võrreldes GPT-2 1,5 miljardiga). See tohutu ulatuse suurenemine koos arhitektuuriliste täiustustega andis kvalitatiivselt erinevaid võimalusi. GPT-3 suutis genereerida märkimisväärselt inimlaadset teksti, mõista konteksti tuhandete sõnade ulatuses ja isegi täita ülesandeid, milleks seda polnud otseselt treenitud. Vestluspõhise tehisintellekti puhul kandusid need edusammud vestlusrobotiteni, mis suutsid:
Säilitada sidusaid vestlusi paljude vestlusvoorude jooksul
Mõista nüansirikkaid päringuid ilma selgesõnalise koolituseta
Genereerida mitmekesiseid, kontekstipõhiseid vastuseid
Kohandada oma tooni ja stiili vastavalt kasutaja vajadustele
Toimetulek ebaselgusega ja vajadusel selgitada
ChatGPT avaldamine 2022. aasta lõpus tõi need võimalused peavoolu, meelitades mõne päeva jooksul pärast selle turuletoomist üle miljoni kasutaja. Ühtäkki oli üldsusel juurdepääs vestluspõhisele tehisintellektile, mis tundus kvalitatiivselt erinev kõigest varasemast – paindlikum, teadlikum ja loomulikum oma suhtluses.
Kiiresti järgnesid ärilised rakendused, kus ettevõtted lisasid suuri keelemudeleid oma klienditeenindusplatvormidesse, sisu loomise tööriistadesse ja tootlikkuse rakendustesse. Kiire kasutuselevõtt peegeldas nii tehnoloogilist hüpet kui ka nende mudelite pakutavat intuitiivset liidest – vestlus on ju inimeste jaoks kõige loomulikum viis suhelda.
Testi OMA Ettevõtet Minutit
Looge oma konto ja käivitage oma AI chatbot minutite jooksul. Täielikult kohandatav, kodeerimine pole vajalik - alustage klientide kaasamisega kohe!
Valmis minutite jooksul
Kodeerimine pole vajalik
100% turvaline
Multimodaalsed võimalused: lisaks ainult tekstipõhistele vestlustele
Kuigi tekst on domineerinud vestluspõhise tehisintellekti arendamises, on viimastel aastatel toimunud liikumine multimodaalsete süsteemide poole, mis suudavad mõista ja genereerida mitut tüüpi meediat. See areng peegeldab inimsuhtluse põhitõde – me ei kasuta ainult sõnu; me žestikuleerime, näitame pilte, joonistame diagramme ja kasutame oma keskkonda tähenduse edastamiseks.
Nägemiskeele mudelid nagu DALL-E, Midjourney ja Stable Diffusion näitasid võimet genereerida pilte tekstikirjeldustest, samas kui nägemisvõimega mudelid nagu GPT-4 suutsid pilte analüüsida ja neid intelligentselt arutada. See avas vestlusliideste jaoks uusi võimalusi:
Klienditeeninduse robotid, mis suudavad analüüsida kahjustatud toodete fotosid
Ostuabilised, mis suudavad piltidelt esemeid tuvastada ja sarnaseid tooteid leida
Hariduslikud tööriistad, mis suudavad selgitada diagramme ja visuaalseid kontseptsioone
Ligipääsetavuse funktsioonid, mis suudavad pilte kirjeldada nägemispuudega kasutajatele
Ka häälevõimalused on dramaatiliselt arenenud. Varased kõneliidesed, nagu IVR (Interactive Voice Response) süsteemid, olid kurikuulsalt frustreerivad, piirdudes jäikade käskude ja menüüstruktuuridega. Kaasaegsed häälassistendid suudavad mõista loomulikke kõnemustreid, arvestada erinevate aktsentide ja kõnetõrgetega ning vastata üha loomulikuma kõlaga sünteesitud häältega.
Nende võimete liitmine loob tõeliselt multimodaalse vestlusliku tehisintellekti, mis suudab sujuvalt vahetada erinevate suhtlusrežiimide vahel vastavalt kontekstile ja kasutaja vajadustele. Kasutaja võib alustada tekstiküsimusega printeri parandamise kohta, saata veateate foto, saada diagrammi, mis tõstab esile asjakohased nupud, ja seejärel lülituda hääljuhistele, samal ajal kui tema käed on remondiga hõivatud.
See multimodaalne lähenemine ei kujuta endast mitte ainult tehnilist edasiminekut, vaid ka põhimõttelist nihet loomulikuma inimese ja arvuti interaktsiooni suunas – kohtuda kasutajatega mis tahes suhtlusrežiimis, mis sobib kõige paremini nende praeguse konteksti ja vajadustega.
Nägemiskeele mudelid nagu DALL-E, Midjourney ja Stable Diffusion näitasid võimet genereerida pilte tekstikirjeldustest, samas kui nägemisvõimega mudelid nagu GPT-4 suutsid pilte analüüsida ja neid intelligentselt arutada. See avas vestlusliideste jaoks uusi võimalusi:
Klienditeeninduse robotid, mis suudavad analüüsida kahjustatud toodete fotosid
Ostuabilised, mis suudavad piltidelt esemeid tuvastada ja sarnaseid tooteid leida
Hariduslikud tööriistad, mis suudavad selgitada diagramme ja visuaalseid kontseptsioone
Ligipääsetavuse funktsioonid, mis suudavad pilte kirjeldada nägemispuudega kasutajatele
Ka häälevõimalused on dramaatiliselt arenenud. Varased kõneliidesed, nagu IVR (Interactive Voice Response) süsteemid, olid kurikuulsalt frustreerivad, piirdudes jäikade käskude ja menüüstruktuuridega. Kaasaegsed häälassistendid suudavad mõista loomulikke kõnemustreid, arvestada erinevate aktsentide ja kõnetõrgetega ning vastata üha loomulikuma kõlaga sünteesitud häältega.
Nende võimete liitmine loob tõeliselt multimodaalse vestlusliku tehisintellekti, mis suudab sujuvalt vahetada erinevate suhtlusrežiimide vahel vastavalt kontekstile ja kasutaja vajadustele. Kasutaja võib alustada tekstiküsimusega printeri parandamise kohta, saata veateate foto, saada diagrammi, mis tõstab esile asjakohased nupud, ja seejärel lülituda hääljuhistele, samal ajal kui tema käed on remondiga hõivatud.
See multimodaalne lähenemine ei kujuta endast mitte ainult tehnilist edasiminekut, vaid ka põhimõttelist nihet loomulikuma inimese ja arvuti interaktsiooni suunas – kohtuda kasutajatega mis tahes suhtlusrežiimis, mis sobib kõige paremini nende praeguse konteksti ja vajadustega.
Otsinguga laiendatud genereerimine: tehisintellekti maandamine faktides
Vaatamata muljetavaldavatele võimalustele on suurtel keelemudelitel loomupärased piirangud. Nad võivad infot "hallutsineerida", esitades enesekindlalt usutavalt kõlavaid, kuid valesid fakte. Nende teadmised piirduvad sellega, mis oli nende treeningandmetes, mis loob teadmiste piirväärtuse. Ja neil puudub võime pääseda juurde reaalajas teabele või spetsiaalsetele andmebaasidele, kui need pole spetsiaalselt selleks loodud.
Nendele väljakutsetele tekkis lahendusena otsingu-laiendatud genereerimine (RAG). Selle asemel, et tugineda ainult treeningu käigus õpitud parameetritele, ühendavad RAG-süsteemid keelemudelite genereerivad võimed otsingumehhanismidega, mis pääsevad juurde välistele teadmusallikatele. Tüüpiline RAG-arhitektuur töötab järgmiselt:
Süsteem saab kasutaja päringu
See otsib asjakohastest teadmusbaasidest päringuga seotud teavet
See edastab nii päringu kui ka hangitud teabe keelemudelile
Mudel genereerib hangitud faktidel põhineva vastuse
See lähenemisviis pakub mitmeid eeliseid:
Täpsemad ja faktipõhised vastused, mis põhinevad genereerimisel kontrollitud teabel
Võimalus pääseda juurde ajakohasele teabele ka pärast mudeli koolituspiiri
Spetsialiseeritud teadmised valdkonnapõhistest allikatest, näiteks ettevõtte dokumentatsioonist
Läbipaistvus ja omistamine teabeallikate viitamise kaudu
Vestluspõhist tehisintellekti rakendavate ettevõtete jaoks on RAG osutunud eriti väärtuslikuks klienditeeninduse rakenduste jaoks. Näiteks pangandusvestlusrobot saab juurde pääseda uusimatele poliitikadokumentidele, kontoteabele ja tehingute andmetele, et pakkuda täpseid ja isikupärastatud vastuseid, mis oleks iseseisva keelemudeliga võimatu.
RAG-süsteemide areng jätkub otsingu täpsuse paranemisega, keerukamate meetoditega hangitud teabe integreerimiseks genereeritud tekstiga ja paremate mehhanismidega erinevate teabeallikate usaldusväärsuse hindamiseks.
Nendele väljakutsetele tekkis lahendusena otsingu-laiendatud genereerimine (RAG). Selle asemel, et tugineda ainult treeningu käigus õpitud parameetritele, ühendavad RAG-süsteemid keelemudelite genereerivad võimed otsingumehhanismidega, mis pääsevad juurde välistele teadmusallikatele. Tüüpiline RAG-arhitektuur töötab järgmiselt:
Süsteem saab kasutaja päringu
See otsib asjakohastest teadmusbaasidest päringuga seotud teavet
See edastab nii päringu kui ka hangitud teabe keelemudelile
Mudel genereerib hangitud faktidel põhineva vastuse
See lähenemisviis pakub mitmeid eeliseid:
Täpsemad ja faktipõhised vastused, mis põhinevad genereerimisel kontrollitud teabel
Võimalus pääseda juurde ajakohasele teabele ka pärast mudeli koolituspiiri
Spetsialiseeritud teadmised valdkonnapõhistest allikatest, näiteks ettevõtte dokumentatsioonist
Läbipaistvus ja omistamine teabeallikate viitamise kaudu
Vestluspõhist tehisintellekti rakendavate ettevõtete jaoks on RAG osutunud eriti väärtuslikuks klienditeeninduse rakenduste jaoks. Näiteks pangandusvestlusrobot saab juurde pääseda uusimatele poliitikadokumentidele, kontoteabele ja tehingute andmetele, et pakkuda täpseid ja isikupärastatud vastuseid, mis oleks iseseisva keelemudeliga võimatu.
RAG-süsteemide areng jätkub otsingu täpsuse paranemisega, keerukamate meetoditega hangitud teabe integreerimiseks genereeritud tekstiga ja paremate mehhanismidega erinevate teabeallikate usaldusväärsuse hindamiseks.
Inimese ja tehisintellekti koostöömudel: õige tasakaalu leidmine
Kuna vestluspõhise tehisintellekti võimalused on laienenud, on arenenud ka inimeste ja tehisintellekti süsteemide vaheline suhe. Varased vestlusrobotid positsioneeriti selgelt tööriistadena – piiratud ulatusega ja ilmselgelt mitteinimlikud oma interaktsioonides. Tänapäevased süsteemid hägustavad neid piire, tekitades uusi küsimusi selle kohta, kuidas kujundada tõhusat inimese ja tehisintellekti koostööd.
Tänapäeva edukaimad rakendused järgivad koostöömudelit, kus:
Tehisintellekt tegeleb rutiinsete, korduvate päringutega, mis ei vaja inimlikku otsustusvõimet.
Inimesed keskenduvad keerukatele juhtumitele, mis nõuavad empaatiat, eetilist mõtlemist või loomingulist probleemide lahendamist.
Süsteem teab oma piiranguid ja eskaleerub sujuvalt inimagentidele, kui see on asjakohane.
Üleminek tehisintellekti ja inimtoe vahel on kasutaja jaoks sujuv.
Inimestel on täielik ülevaade tehisintellektiga peetud vestluste ajaloost.
Tehisintellekt õpib pidevalt inimeste sekkumistest, laiendades järk-järgult oma võimalusi.
See lähenemisviis tunnistab, et vestluspõhine tehisintellekt ei tohiks olla suunatud inimsuhtluse täielikule asendamisele, vaid pigem selle täiendamisele – käsitledes suuremahulisi ja lihtsaid päringuid, mis tarbivad inimagentide aega, tagades samal ajal, et keerulised küsimused jõuavad õigete inimlike ekspertideni.
Selle mudeli rakendamine on tööstusharudes erinev. Tervishoius võivad tehisintellektil põhinevad vestlusrobotid tegeleda kohtumiste broneerimise ja sümptomite põhilise kontrollimisega, tagades samal ajal, et meditsiiniline nõu tuleb kvalifitseeritud spetsialistidelt. Õigusteenustes võib tehisintellekt aidata dokumentide ettevalmistamise ja uurimisega, jättes tõlgendamise ja strateegia juristidele. Klienditeeninduses saab tehisintellekt lahendada levinud probleeme, suunates keerulised probleemid spetsialiseerunud agentidele.
Tehisintellekti võimekuse pideva arenedes nihkub piir selle vahel, mis nõuab inimlikku sekkumist, ja selle vahel, mida saab automatiseerida, kuid põhiprintsiip jääb samaks: tõhus vestluslik tehisintellekt peaks inimvõimeid parandama, mitte lihtsalt neid asendama.
Tänapäeva edukaimad rakendused järgivad koostöömudelit, kus:
Tehisintellekt tegeleb rutiinsete, korduvate päringutega, mis ei vaja inimlikku otsustusvõimet.
Inimesed keskenduvad keerukatele juhtumitele, mis nõuavad empaatiat, eetilist mõtlemist või loomingulist probleemide lahendamist.
Süsteem teab oma piiranguid ja eskaleerub sujuvalt inimagentidele, kui see on asjakohane.
Üleminek tehisintellekti ja inimtoe vahel on kasutaja jaoks sujuv.
Inimestel on täielik ülevaade tehisintellektiga peetud vestluste ajaloost.
Tehisintellekt õpib pidevalt inimeste sekkumistest, laiendades järk-järgult oma võimalusi.
See lähenemisviis tunnistab, et vestluspõhine tehisintellekt ei tohiks olla suunatud inimsuhtluse täielikule asendamisele, vaid pigem selle täiendamisele – käsitledes suuremahulisi ja lihtsaid päringuid, mis tarbivad inimagentide aega, tagades samal ajal, et keerulised küsimused jõuavad õigete inimlike ekspertideni.
Selle mudeli rakendamine on tööstusharudes erinev. Tervishoius võivad tehisintellektil põhinevad vestlusrobotid tegeleda kohtumiste broneerimise ja sümptomite põhilise kontrollimisega, tagades samal ajal, et meditsiiniline nõu tuleb kvalifitseeritud spetsialistidelt. Õigusteenustes võib tehisintellekt aidata dokumentide ettevalmistamise ja uurimisega, jättes tõlgendamise ja strateegia juristidele. Klienditeeninduses saab tehisintellekt lahendada levinud probleeme, suunates keerulised probleemid spetsialiseerunud agentidele.
Tehisintellekti võimekuse pideva arenedes nihkub piir selle vahel, mis nõuab inimlikku sekkumist, ja selle vahel, mida saab automatiseerida, kuid põhiprintsiip jääb samaks: tõhus vestluslik tehisintellekt peaks inimvõimeid parandama, mitte lihtsalt neid asendama.
Tulevikumaastik: kuhu vestluspõhine tehisintellekt suundub
Vaadates tulevikku, kujundavad mitmed tekkivad trendid vestluspõhise tehisintellekti tulevikku. Need arengud lubavad mitte ainult järkjärgulisi täiustusi, vaid potentsiaalselt ka transformatiivseid muutusi selles, kuidas me tehnoloogiaga suhtleme.
Suurepärane isikupärastamine: Tulevikusüsteemid kohandavad oma vastuseid üha enam mitte ainult vahetu konteksti, vaid ka iga kasutaja suhtlusstiili, eelistuste, teadmiste taseme ja suhete ajaloo järgi. See isikupärastamine muudab suhtluse loomulikumaks ja asjakohasemaks, kuigi see tekitab olulisi küsimusi privaatsuse ja andmete kasutamise kohta.
Emotsionaalne intelligentsus: Kuigi tänapäeva süsteemid suudavad tuvastada põhilisi tundeid, arendab tulevane vestluspõhine tehisintellekt keerukamat emotsionaalset intelligentsust – see tunneb ära peeneid emotsionaalseid seisundeid, reageerib asjakohaselt stressile või frustratsioonile ning kohandab vastavalt oma tooni ja lähenemisviisi. See võime on eriti väärtuslik klienditeeninduse, tervishoiu ja hariduse rakendustes.
Proaktiivne abi: Selle asemel, et oodata selgesõnalisi päringuid, ennustavad järgmise põlvkonna vestlussüsteemid vajadusi konteksti, kasutaja ajaloo ja keskkonnasignaalide põhjal. Süsteem võib märgata, et planeerite mitut kohtumist võõras linnas, ja pakkuda proaktiivselt transpordivõimalusi või ilmateateid.
Sujuv multimodaalne integratsioon: Tulevikusüsteemid liiguvad erinevate transpordiliikide toetamisest kaugemale nende sujuva integreerimise poole. Vestlus võib kulgeda loomulikult teksti, hääle, piltide ja interaktiivsete elementide vahel, valides iga teabeüksuse jaoks õige meetodi ilma kasutajapoolset valikut nõudmata.
Spetsialiseerunud valdkonnaeksperdid: Kuigi üldotstarbelised assistendid arenevad pidevalt, näeme ka kõrgelt spetsialiseerunud vestluspõhise tehisintellekti esiletõusu, millel on sügavad teadmised konkreetsetes valdkondades – õigusabilised, kes mõistavad kohtupraktikat ja pretsedente, meditsiinisüsteemid, kellel on põhjalikud teadmised ravimite koostoimetest ja raviprotokollidest, või finantsnõustajad, kes on kursis maksuseadustike ja investeerimisstrateegiatega.
Tõeliselt pidev õppimine: Tulevikusüsteemid liiguvad perioodilisest ümberõppest pideva õppimiseni suhtlustest, muutudes aja jooksul abivalmimaks ja isikupärasemaks, säilitades samal ajal asjakohased privaatsuskaitsemeetmed.
Vaatamata neile põnevatele võimalustele on endiselt probleeme. Privaatsusprobleemid, eelarvamuste leevendamine, asjakohane läbipaistvus ja õige taseme inimjärelevalve loomine on pidevad küsimused, mis kujundavad nii tehnoloogiat kui ka selle reguleerimist. Kõige edukamad rakendused on need, mis käsitlevad neid väljakutseid läbimõeldult, pakkudes samal ajal kasutajatele tõelist väärtust.
On selge, et vestluspõhine tehisintellekt on liikunud nišitehnoloogiast peavoolu liidese paradigmaks, mis vahendab üha enam meie suhtlust digitaalsete süsteemidega. Evolutsioonitee ELIZA lihtsast mustrite sobitamisest tänapäevaste keerukate keelemudeliteni on üks olulisemaid edusamme inimese ja arvuti interaktsioonis – ja teekond pole kaugeltki läbi.
Suurepärane isikupärastamine: Tulevikusüsteemid kohandavad oma vastuseid üha enam mitte ainult vahetu konteksti, vaid ka iga kasutaja suhtlusstiili, eelistuste, teadmiste taseme ja suhete ajaloo järgi. See isikupärastamine muudab suhtluse loomulikumaks ja asjakohasemaks, kuigi see tekitab olulisi küsimusi privaatsuse ja andmete kasutamise kohta.
Emotsionaalne intelligentsus: Kuigi tänapäeva süsteemid suudavad tuvastada põhilisi tundeid, arendab tulevane vestluspõhine tehisintellekt keerukamat emotsionaalset intelligentsust – see tunneb ära peeneid emotsionaalseid seisundeid, reageerib asjakohaselt stressile või frustratsioonile ning kohandab vastavalt oma tooni ja lähenemisviisi. See võime on eriti väärtuslik klienditeeninduse, tervishoiu ja hariduse rakendustes.
Proaktiivne abi: Selle asemel, et oodata selgesõnalisi päringuid, ennustavad järgmise põlvkonna vestlussüsteemid vajadusi konteksti, kasutaja ajaloo ja keskkonnasignaalide põhjal. Süsteem võib märgata, et planeerite mitut kohtumist võõras linnas, ja pakkuda proaktiivselt transpordivõimalusi või ilmateateid.
Sujuv multimodaalne integratsioon: Tulevikusüsteemid liiguvad erinevate transpordiliikide toetamisest kaugemale nende sujuva integreerimise poole. Vestlus võib kulgeda loomulikult teksti, hääle, piltide ja interaktiivsete elementide vahel, valides iga teabeüksuse jaoks õige meetodi ilma kasutajapoolset valikut nõudmata.
Spetsialiseerunud valdkonnaeksperdid: Kuigi üldotstarbelised assistendid arenevad pidevalt, näeme ka kõrgelt spetsialiseerunud vestluspõhise tehisintellekti esiletõusu, millel on sügavad teadmised konkreetsetes valdkondades – õigusabilised, kes mõistavad kohtupraktikat ja pretsedente, meditsiinisüsteemid, kellel on põhjalikud teadmised ravimite koostoimetest ja raviprotokollidest, või finantsnõustajad, kes on kursis maksuseadustike ja investeerimisstrateegiatega.
Tõeliselt pidev õppimine: Tulevikusüsteemid liiguvad perioodilisest ümberõppest pideva õppimiseni suhtlustest, muutudes aja jooksul abivalmimaks ja isikupärasemaks, säilitades samal ajal asjakohased privaatsuskaitsemeetmed.
Vaatamata neile põnevatele võimalustele on endiselt probleeme. Privaatsusprobleemid, eelarvamuste leevendamine, asjakohane läbipaistvus ja õige taseme inimjärelevalve loomine on pidevad küsimused, mis kujundavad nii tehnoloogiat kui ka selle reguleerimist. Kõige edukamad rakendused on need, mis käsitlevad neid väljakutseid läbimõeldult, pakkudes samal ajal kasutajatele tõelist väärtust.
On selge, et vestluspõhine tehisintellekt on liikunud nišitehnoloogiast peavoolu liidese paradigmaks, mis vahendab üha enam meie suhtlust digitaalsete süsteemidega. Evolutsioonitee ELIZA lihtsast mustrite sobitamisest tänapäevaste keerukate keelemudeliteni on üks olulisemaid edusamme inimese ja arvuti interaktsioonis – ja teekond pole kaugeltki läbi.





