Testi tehisintellekti OMA veebisaidil 60 sekundiga
Vaata, kuidas meie tehisintellekt analüüsib koheselt sinu veebisaiti ja loob personaliseeritud vestlusroboti - ilma registreerimiseta. Sisesta lihtsalt oma URL ja jälgi, kuidas see toimib!
Valmis 60 sekundiga
Programmeerimist pole vaja
100% turvaline
Alandlik algus: varajased reeglipõhised süsteemid
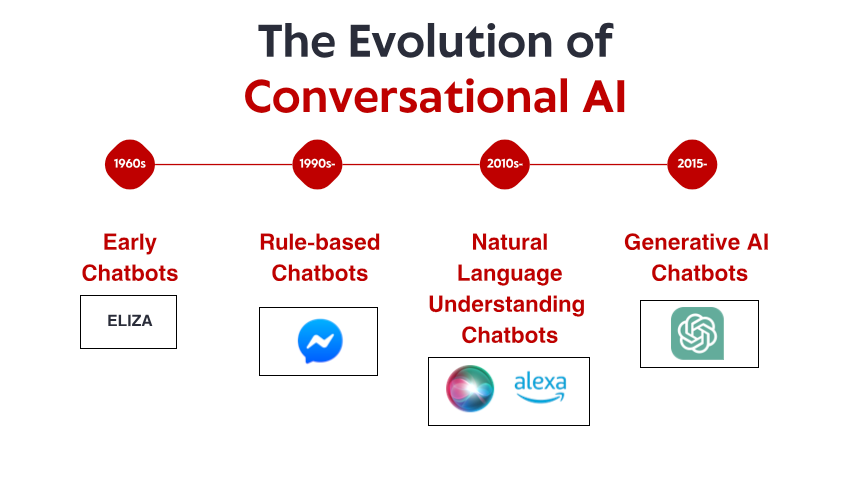
Vestluspõhise tehisintellekti lugu saab alguse 1960. aastatest, ammu enne seda, kui nutitelefonid ja häälassistendid muutusid koduseks põhitarbeks. MIT-i väikeses laboris lõi arvutiteadlane Joseph Weizenbaum selle, mida paljud peavad esimeseks vestlusbotiks: ELIZA. Rogeria psühhoterapeudi simuleerimiseks loodud ELIZA töötas läbi lihtsate mustrite sobitamise ja asendusreeglite. Kui kasutaja kirjutas "Ma tunnen end kurvalt", võib ELIZA vastata sõnadega "Miks sa kurb tunned?" – arusaamise illusiooni loomine väidete küsimustena ümber sõnastades.
ELIZA tegi tähelepanuväärseks mitte selle tehniline keerukus – tänapäevaste standardite järgi oli programm uskumatult elementaarne. Pigem oli see kasutajatele avaldatud sügav mõju. Vaatamata teadmisele, et nad räägivad arvutiprogrammiga, ilma tegelikust arusaamisest, tekkisid paljud inimesed ELIZA-ga emotsionaalsed sidemed, jagades sügavalt isiklikke mõtteid ja tundeid. See nähtus, mida Weizenbaum ise pidas häirivaks, paljastas midagi põhjapanevat inimpsühholoogias ja meie valmisolekus antropomorfiseerida isegi kõige lihtsamaid vestlusliideseid.
Läbi 1970. ja 1980. aastate järgisid reeglipõhised vestlusrobotid ELIZA malli koos järkjärguliste täiustustega. Sellised programmid nagu PARRY (simuleerib paranoilist skisofreenikut) ja RACTER (mille autoriks oli raamat nimega "Politseiniku habe on pooleldi ehitatud") jäid kindlalt reeglipõhise paradigma piiridesse – kasutades eelnevalt määratletud mustreid, märksõnade sobitamist ja malli vastuseid.
Nendel varastel süsteemidel olid tõsised piirangud. Nad ei saanud tegelikult keelest aru, interaktsioonidest õppida ega ootamatute sisenditega kohaneda. Nende teadmised piirdusid reeglitega, mille nende programmeerijad olid selgelt määratlenud. Kui kasutajad paratamatult nendest piiridest välja eksisid, purunes luure illusioon kiiresti, paljastades selle all oleva mehaanilise olemuse. Vaatamata nendele piirangutele lõid need teedrajavad süsteemid aluse, millele kogu tulevane vestluspõhine AI toetub.
ELIZA tegi tähelepanuväärseks mitte selle tehniline keerukus – tänapäevaste standardite järgi oli programm uskumatult elementaarne. Pigem oli see kasutajatele avaldatud sügav mõju. Vaatamata teadmisele, et nad räägivad arvutiprogrammiga, ilma tegelikust arusaamisest, tekkisid paljud inimesed ELIZA-ga emotsionaalsed sidemed, jagades sügavalt isiklikke mõtteid ja tundeid. See nähtus, mida Weizenbaum ise pidas häirivaks, paljastas midagi põhjapanevat inimpsühholoogias ja meie valmisolekus antropomorfiseerida isegi kõige lihtsamaid vestlusliideseid.
Läbi 1970. ja 1980. aastate järgisid reeglipõhised vestlusrobotid ELIZA malli koos järkjärguliste täiustustega. Sellised programmid nagu PARRY (simuleerib paranoilist skisofreenikut) ja RACTER (mille autoriks oli raamat nimega "Politseiniku habe on pooleldi ehitatud") jäid kindlalt reeglipõhise paradigma piiridesse – kasutades eelnevalt määratletud mustreid, märksõnade sobitamist ja malli vastuseid.
Nendel varastel süsteemidel olid tõsised piirangud. Nad ei saanud tegelikult keelest aru, interaktsioonidest õppida ega ootamatute sisenditega kohaneda. Nende teadmised piirdusid reeglitega, mille nende programmeerijad olid selgelt määratlenud. Kui kasutajad paratamatult nendest piiridest välja eksisid, purunes luure illusioon kiiresti, paljastades selle all oleva mehaanilise olemuse. Vaatamata nendele piirangutele lõid need teedrajavad süsteemid aluse, millele kogu tulevane vestluspõhine AI toetub.
Teadmiste revolutsioon: ekspertsüsteemid ja struktureeritud teave
1980ndatel ja 1990ndate alguses tõusid esile ekspertsüsteemid – tehisintellekti programmid, mis on loodud keeruliste probleemide lahendamiseks, matkides inimekspertide otsustusvõimet konkreetsetes valdkondades. Kuigi need süsteemid ei ole mõeldud peamiselt vestluseks, kujutasid need endast olulist evolutsioonilist sammu vestlusliku tehisintellekti jaoks, tuues kasutusele keerukama teadmiste esituse.
Ekspertsüsteemid nagu MYCIN (mis diagnoosis bakteriaalseid infektsioone) ja DENDRAL (mis tuvastas keemilised ühendid) korraldasid teabe struktureeritud teadmistebaasides ja kasutasid järelduste tegemiseks järeldusmootoreid. Vestlusliidestes rakendatuna võimaldas see lähenemisviis vestlusrobotidel liikuda lihtsast mustrite sobitamisest kaugemale, millegi arutluskäiku meenutava poole suunas – vähemalt kitsastes valdkondades.
Ettevõtted hakkasid seda tehnoloogiat kasutades rakendama praktilisi rakendusi, nagu automatiseeritud klienditeenindussüsteeme. Need süsteemid kasutasid tavaliselt otsustuspuid ja menüüpõhiseid interaktsioone, mitte vabas vormis vestlust, kuid need kujutasid endast varaseid katseid automatiseerida interaktsioone, mis varem nõudsid inimese sekkumist.
Piirangud jäid märkimisväärseks. Need süsteemid olid rabedad ega suutnud ootamatuid sisendeid graatsiliselt käsitleda. Need nõudsid teadmiste inseneridelt tohutuid jõupingutusi teabe ja reeglite käsitsi kodeerimiseks. Ja võib-olla mis kõige tähtsam, nad ei saanud ikka veel päriselt aru loomulikust keelest selle täies keerukuses ja mitmetähenduslikkuses.
Sellegipoolest kehtestas see ajastu olulised mõisted, mis said hiljem kaasaegse vestluse AI jaoks ülioluliseks: struktureeritud teadmiste esitus, loogiline järeldus ja domeeni spetsialiseerumine. Paradigma muutuseks valmistati lava, kuigi tehnoloogia polnud veel päris valmis.
Ekspertsüsteemid nagu MYCIN (mis diagnoosis bakteriaalseid infektsioone) ja DENDRAL (mis tuvastas keemilised ühendid) korraldasid teabe struktureeritud teadmistebaasides ja kasutasid järelduste tegemiseks järeldusmootoreid. Vestlusliidestes rakendatuna võimaldas see lähenemisviis vestlusrobotidel liikuda lihtsast mustrite sobitamisest kaugemale, millegi arutluskäiku meenutava poole suunas – vähemalt kitsastes valdkondades.
Ettevõtted hakkasid seda tehnoloogiat kasutades rakendama praktilisi rakendusi, nagu automatiseeritud klienditeenindussüsteeme. Need süsteemid kasutasid tavaliselt otsustuspuid ja menüüpõhiseid interaktsioone, mitte vabas vormis vestlust, kuid need kujutasid endast varaseid katseid automatiseerida interaktsioone, mis varem nõudsid inimese sekkumist.
Piirangud jäid märkimisväärseks. Need süsteemid olid rabedad ega suutnud ootamatuid sisendeid graatsiliselt käsitleda. Need nõudsid teadmiste inseneridelt tohutuid jõupingutusi teabe ja reeglite käsitsi kodeerimiseks. Ja võib-olla mis kõige tähtsam, nad ei saanud ikka veel päriselt aru loomulikust keelest selle täies keerukuses ja mitmetähenduslikkuses.
Sellegipoolest kehtestas see ajastu olulised mõisted, mis said hiljem kaasaegse vestluse AI jaoks ülioluliseks: struktureeritud teadmiste esitus, loogiline järeldus ja domeeni spetsialiseerumine. Paradigma muutuseks valmistati lava, kuigi tehnoloogia polnud veel päris valmis.
Loomuliku keele mõistmine: arvutuslingvistika läbimurre
1990ndate lõpus ja 2000ndate alguses hakati üha enam keskenduma loomuliku keele töötlemisele (NLP) ja arvutuslingvistikale. Selle asemel, et püüda käsitsi kodeerida reegleid iga võimaliku suhtluse jaoks, hakkasid teadlased välja töötama statistilisi meetodeid, mis aitavad arvutitel mõista inimkeelele omaseid mustreid.
Seda nihet võimaldasid mitmed tegurid: arvutusvõimsuse suurenemine, paremad algoritmid ja, mis kõige tähtsam, suurte tekstikorpuste kättesaadavus, mida saaks analüüsida keeleliste mustrite tuvastamiseks. Süsteemid hakkasid hõlmama selliseid tehnikaid nagu:
Kõneosa märgistamine: tuvastab, kas sõnad toimisid nimisõnadena, tegusõnadena, omadussõnadena jne.
Nimetatud olemi tuvastamine: pärisnimede (inimesed, organisatsioonid, asukohad) tuvastamine ja klassifitseerimine.
Tundeanalüüs: teksti emotsionaalse tooni määramine.
Sõelumine: lausestruktuuri analüüs sõnadevaheliste grammatiliste seoste tuvastamiseks.
Üks märkimisväärne läbimurre tuli IBM-i Watsoniga, mis alistas viktoriinil Jeopardy kuulsalt inimtšempionid! 2011. aastal. Kuigi Watson ei olnud rangelt vestlussüsteem, demonstreeris ta enneolematut võimet mõista loomuliku keele küsimusi, otsida tohututest teadmistehoidlatest ja sõnastada vastuseid – võimeid, mis osutuvad järgmise põlvkonna vestlusrobotite jaoks hädavajalikuks.
Peagi järgnesid kommertsrakendused. Apple'i Siri toodi turule 2011. aastal, tuues tavatarbijateni vestlusliidesed. Kuigi Siri on tänapäevaste standarditega piiratud, oli see märkimisväärne edusamm AI-assistentide igapäevastele kasutajatele kättesaadavaks tegemisel. Järgnevad Microsofti Cortana, Google'i assistent ja Amazoni Alexa, mis kumbki edendavad tarbijatele suunatud vestluse AI tehnika taset.
Nendest edusammudest hoolimata võitlesid selle ajastu süsteemid endiselt konteksti, terve mõistuse arutluskäigu ja tõeliselt loomuliku kõlaga vastuste tekitamisega. Nad olid keerukamad kui nende reeglitel põhinevad esivanemad, kuid jäid oma keele ja maailma mõistmisel põhimõtteliselt piiratuks.
Seda nihet võimaldasid mitmed tegurid: arvutusvõimsuse suurenemine, paremad algoritmid ja, mis kõige tähtsam, suurte tekstikorpuste kättesaadavus, mida saaks analüüsida keeleliste mustrite tuvastamiseks. Süsteemid hakkasid hõlmama selliseid tehnikaid nagu:
Kõneosa märgistamine: tuvastab, kas sõnad toimisid nimisõnadena, tegusõnadena, omadussõnadena jne.
Nimetatud olemi tuvastamine: pärisnimede (inimesed, organisatsioonid, asukohad) tuvastamine ja klassifitseerimine.
Tundeanalüüs: teksti emotsionaalse tooni määramine.
Sõelumine: lausestruktuuri analüüs sõnadevaheliste grammatiliste seoste tuvastamiseks.
Üks märkimisväärne läbimurre tuli IBM-i Watsoniga, mis alistas viktoriinil Jeopardy kuulsalt inimtšempionid! 2011. aastal. Kuigi Watson ei olnud rangelt vestlussüsteem, demonstreeris ta enneolematut võimet mõista loomuliku keele küsimusi, otsida tohututest teadmistehoidlatest ja sõnastada vastuseid – võimeid, mis osutuvad järgmise põlvkonna vestlusrobotite jaoks hädavajalikuks.
Peagi järgnesid kommertsrakendused. Apple'i Siri toodi turule 2011. aastal, tuues tavatarbijateni vestlusliidesed. Kuigi Siri on tänapäevaste standarditega piiratud, oli see märkimisväärne edusamm AI-assistentide igapäevastele kasutajatele kättesaadavaks tegemisel. Järgnevad Microsofti Cortana, Google'i assistent ja Amazoni Alexa, mis kumbki edendavad tarbijatele suunatud vestluse AI tehnika taset.
Nendest edusammudest hoolimata võitlesid selle ajastu süsteemid endiselt konteksti, terve mõistuse arutluskäigu ja tõeliselt loomuliku kõlaga vastuste tekitamisega. Nad olid keerukamad kui nende reeglitel põhinevad esivanemad, kuid jäid oma keele ja maailma mõistmisel põhimõtteliselt piiratuks.
Masinõpe ja andmepõhine lähenemine
2010. aastate keskpaik tähistas järjekordset paradigma muutust vestluspõhises tehisintellektis koos masinõppemeetodite kasutuselevõtuga. Selle asemel, et tugineda käsitsi koostatud reeglitele või piiratud statistilistele mudelitele, hakkasid insenerid ehitama süsteeme, mis võiksid õppida mustreid otse andmetest – ja paljudest neist.
Sellel ajastul kasvas vestlusarhitektuuri põhikomponentidena kavatsuste klassifitseerimine ja üksuste eraldamine. Kui kasutaja esitas päringu, teeks süsteem järgmist:
Liigitage üldine kavatsus (nt lennu broneerimine, ilmateate kontrollimine, muusika esitamine)
Ekstraktige asjakohased üksused (nt asukohad, kuupäevad, laulude pealkirjad)
Kaardista need konkreetsete tegevuste või vastustega
Facebooki (praegu Meta) Messengeri platvormi käivitamine 2016. aastal võimaldas arendajatel luua vestlusroboteid, mis võivad jõuda miljonite kasutajateni, tekitades ärihuvi. Paljud ettevõtted tormasid vestlusroboteid juurutama, kuigi tulemused olid erinevad. Varased kommertsrakendused valmistasid kasutajatele sageli meelehärmi piiratud arusaamise ja jäikade vestlusvoogude tõttu.
Sel perioodil arenes välja ka vestlussüsteemide tehniline arhitektuur. Tüüpiline lähenemisviis hõlmas spetsiaalsete komponentide torustikku:
Automaatne kõnetuvastus (häälliideste jaoks)
Loomuliku keele mõistmine
Dialoogihaldus
Loomuliku keele põlvkond
Tekst kõneks (häälliideste jaoks)
Iga komponenti saab eraldi optimeerida, võimaldades järkjärgulisi täiustusi. Kuid need torujuhtmete arhitektuurid kannatasid mõnikord vigade levimise all – varases staadiumis esinevad vead levisid süsteemist läbi.
Kuigi masinõpe parandas oluliselt võimalusi, olid süsteemid endiselt hädas pikkade vestluste konteksti säilitamise, kaudse teabe mõistmise ning tõeliselt mitmekesiste ja loomulike vastuste genereerimisega. Järgmine läbimurre eeldaks radikaalsemat lähenemist.
Sellel ajastul kasvas vestlusarhitektuuri põhikomponentidena kavatsuste klassifitseerimine ja üksuste eraldamine. Kui kasutaja esitas päringu, teeks süsteem järgmist:
Liigitage üldine kavatsus (nt lennu broneerimine, ilmateate kontrollimine, muusika esitamine)
Ekstraktige asjakohased üksused (nt asukohad, kuupäevad, laulude pealkirjad)
Kaardista need konkreetsete tegevuste või vastustega
Facebooki (praegu Meta) Messengeri platvormi käivitamine 2016. aastal võimaldas arendajatel luua vestlusroboteid, mis võivad jõuda miljonite kasutajateni, tekitades ärihuvi. Paljud ettevõtted tormasid vestlusroboteid juurutama, kuigi tulemused olid erinevad. Varased kommertsrakendused valmistasid kasutajatele sageli meelehärmi piiratud arusaamise ja jäikade vestlusvoogude tõttu.
Sel perioodil arenes välja ka vestlussüsteemide tehniline arhitektuur. Tüüpiline lähenemisviis hõlmas spetsiaalsete komponentide torustikku:
Automaatne kõnetuvastus (häälliideste jaoks)
Loomuliku keele mõistmine
Dialoogihaldus
Loomuliku keele põlvkond
Tekst kõneks (häälliideste jaoks)
Iga komponenti saab eraldi optimeerida, võimaldades järkjärgulisi täiustusi. Kuid need torujuhtmete arhitektuurid kannatasid mõnikord vigade levimise all – varases staadiumis esinevad vead levisid süsteemist läbi.
Kuigi masinõpe parandas oluliselt võimalusi, olid süsteemid endiselt hädas pikkade vestluste konteksti säilitamise, kaudse teabe mõistmise ning tõeliselt mitmekesiste ja loomulike vastuste genereerimisega. Järgmine läbimurre eeldaks radikaalsemat lähenemist.
Transformaatorite revolutsioon: närvikeele mudelid
2017. aasta tähistas AI ajaloos veelahelikku hetke, kui avaldati "Attention Is All You Need", mis tutvustas Transformeri arhitektuuri, mis muudaks pöörde loomuliku keele töötlemiseks. Erinevalt varasematest lähenemisviisidest, mis töödeldi teksti järjestikku, võisid Transformers kaaluda tervet lõiku üheaegselt, võimaldades neil paremini tabada sõnade vahelisi suhteid, olenemata nende kaugusest üksteisest.
See uuendus võimaldas välja töötada üha võimsamaid keelemudeleid. 2018. aastal tutvustas Google BERT-i (Bidirectional Encoder Representations from Transformers), mis parandas märkimisväärselt erinevate keelemõistmise ülesannete toimivust. 2019. aastal andis OpenAI välja GPT-2, demonstreerides enneolematuid võimeid sidusa ja kontekstuaalselt asjakohase teksti loomisel.
Kõige dramaatilisem hüpe toimus 2020. aastal GPT-3-ga, mis ulatus 175 miljardi parameetrini (võrreldes GPT-2 1,5 miljardiga). See tohutu mastaabi suurenemine koos arhitektuuriliste täiustustega andis kvalitatiivselt erinevaid võimalusi. GPT-3 suutis genereerida märkimisväärselt inimesesarnast teksti, mõista tuhandete sõnade konteksti ja täita isegi ülesandeid, milleks see selgesõnaliselt välja õpetatud ei olnud.
Vestluspõhise AI puhul tõlgiti need edusammud vestlusrobotiks, mis võiksid:
Säilitage sidusaid vestlusi mitmel pöördel
Saate aru nüansirikastest päringutest ilma selgesõnalise koolituseta
Looge erinevaid, kontekstipõhiseid vastuseid
Kohandage nende toon ja stiil vastavalt kasutajale
Käsitlege ebaselgust ja vajadusel täpsustage
ChatGPT väljalaskmine 2022. aasta lõpus tõi need võimalused peavoolu, meelitades päevade jooksul pärast selle käivitamist üle miljoni kasutaja. Järsku avanes avalikkusele juurdepääs vestluspõhisele AI-le, mis tundus kvalitatiivselt erinev kõigest varasemast – paindlikum, teadlikum ja omavahelises suhtluses loomulikum.
Kiiresti järgnesid kommertsrakendused, kus ettevõtted lisasid oma klienditeenindusplatvormidesse, sisu loomise tööriistadesse ja tootlikkuse rakendustesse suuri keelemudeleid. Kiire kasutuselevõtt peegeldas nii tehnoloogilist hüpet kui ka nende mudelite pakutavat intuitiivset liidest – vestlus on ju inimeste jaoks kõige loomulikum suhtlemisviis.
See uuendus võimaldas välja töötada üha võimsamaid keelemudeleid. 2018. aastal tutvustas Google BERT-i (Bidirectional Encoder Representations from Transformers), mis parandas märkimisväärselt erinevate keelemõistmise ülesannete toimivust. 2019. aastal andis OpenAI välja GPT-2, demonstreerides enneolematuid võimeid sidusa ja kontekstuaalselt asjakohase teksti loomisel.
Kõige dramaatilisem hüpe toimus 2020. aastal GPT-3-ga, mis ulatus 175 miljardi parameetrini (võrreldes GPT-2 1,5 miljardiga). See tohutu mastaabi suurenemine koos arhitektuuriliste täiustustega andis kvalitatiivselt erinevaid võimalusi. GPT-3 suutis genereerida märkimisväärselt inimesesarnast teksti, mõista tuhandete sõnade konteksti ja täita isegi ülesandeid, milleks see selgesõnaliselt välja õpetatud ei olnud.
Vestluspõhise AI puhul tõlgiti need edusammud vestlusrobotiks, mis võiksid:
Säilitage sidusaid vestlusi mitmel pöördel
Saate aru nüansirikastest päringutest ilma selgesõnalise koolituseta
Looge erinevaid, kontekstipõhiseid vastuseid
Kohandage nende toon ja stiil vastavalt kasutajale
Käsitlege ebaselgust ja vajadusel täpsustage
ChatGPT väljalaskmine 2022. aasta lõpus tõi need võimalused peavoolu, meelitades päevade jooksul pärast selle käivitamist üle miljoni kasutaja. Järsku avanes avalikkusele juurdepääs vestluspõhisele AI-le, mis tundus kvalitatiivselt erinev kõigest varasemast – paindlikum, teadlikum ja omavahelises suhtluses loomulikum.
Kiiresti järgnesid kommertsrakendused, kus ettevõtted lisasid oma klienditeenindusplatvormidesse, sisu loomise tööriistadesse ja tootlikkuse rakendustesse suuri keelemudeleid. Kiire kasutuselevõtt peegeldas nii tehnoloogilist hüpet kui ka nende mudelite pakutavat intuitiivset liidest – vestlus on ju inimeste jaoks kõige loomulikum suhtlemisviis.
Testi tehisintellekti OMA veebisaidil 60 sekundiga
Vaata, kuidas meie tehisintellekt analüüsib koheselt sinu veebisaiti ja loob personaliseeritud vestlusroboti - ilma registreerimiseta. Sisesta lihtsalt oma URL ja jälgi, kuidas see toimib!
Valmis 60 sekundiga
Programmeerimist pole vaja
100% turvaline
Multimodaalsed võimalused: väljaspool ainult tekstivestlusi
Kuigi tekst on domineerinud vestluse AI arendamisel, on viimastel aastatel toimunud tõuge multimodaalsete süsteemide poole, mis suudavad mõista ja luua mitut tüüpi meediume. See areng peegeldab fundamentaalset tõde inimestevahelise suhtluse kohta – me ei kasuta ainult sõnu; žestikuleerime, näitame pilte, joonistame skeeme ja kasutame oma keskkonda tähenduse edastamiseks.
Nägemiskeelsed mudelid, nagu DALL-E, Midjourney ja Stable Diffusion, näitasid võimet luua pilte tekstiliste kirjelduste põhjal, samas kui nägemisvõimega mudelid nagu GPT-4 suutsid pilte analüüsida ja arukalt arutada. See avas uusi võimalusi vestlusliidesteks:
Klienditeeninduse robotid, mis suudavad analüüsida kahjustatud toodete fotosid
Ostuabilised, kes suudavad piltidelt esemeid tuvastada ja sarnaseid tooteid leida
Õppevahendid, millega saab selgitada diagramme ja visuaalseid mõisteid
Juurdepääsetavusfunktsioonid, mis kirjeldavad pilte nägemispuudega kasutajatele
Ka häälevõimekus on järsult arenenud. Varased kõneliidesed, nagu IVR (Interactive Voice Response) süsteemid, olid kurikuulsalt frustreerivad, piirdudes jäikade käskude ja menüüstruktuuridega. Kaasaegsed hääleassistendid suudavad mõista loomulikke kõnemustreid, arvestada erinevate aktsentide ja kõnetakistustega ning vastata üha loomulikuma kõlaga sünteesitud häältega.
Nende võimaluste liit loob tõeliselt multimodaalse vestluspõhise AI, mis suudab kontekstist ja kasutajate vajadustest lähtuvalt sujuvalt lülituda erinevate suhtlusrežiimide vahel. Kasutaja võib alustada tekstiküsimusega printeri parandamise kohta, saata veateatest foto, saada asjakohaseid nuppe esile tõstva diagrammi ja seejärel lülituda hääljuhistele, kui tema käed on remondiga hõivatud.
See multimodaalne lähenemine ei kujuta endast mitte ainult tehnilist edusamme, vaid ka põhjapanevat nihet loomulikuma inimese ja arvuti suhtluse poole – kasutajatega kohtumine mis tahes suhtlusrežiimis, mis nende praeguse konteksti ja vajaduste jaoks kõige paremini sobib.
Nägemiskeelsed mudelid, nagu DALL-E, Midjourney ja Stable Diffusion, näitasid võimet luua pilte tekstiliste kirjelduste põhjal, samas kui nägemisvõimega mudelid nagu GPT-4 suutsid pilte analüüsida ja arukalt arutada. See avas uusi võimalusi vestlusliidesteks:
Klienditeeninduse robotid, mis suudavad analüüsida kahjustatud toodete fotosid
Ostuabilised, kes suudavad piltidelt esemeid tuvastada ja sarnaseid tooteid leida
Õppevahendid, millega saab selgitada diagramme ja visuaalseid mõisteid
Juurdepääsetavusfunktsioonid, mis kirjeldavad pilte nägemispuudega kasutajatele
Ka häälevõimekus on järsult arenenud. Varased kõneliidesed, nagu IVR (Interactive Voice Response) süsteemid, olid kurikuulsalt frustreerivad, piirdudes jäikade käskude ja menüüstruktuuridega. Kaasaegsed hääleassistendid suudavad mõista loomulikke kõnemustreid, arvestada erinevate aktsentide ja kõnetakistustega ning vastata üha loomulikuma kõlaga sünteesitud häältega.
Nende võimaluste liit loob tõeliselt multimodaalse vestluspõhise AI, mis suudab kontekstist ja kasutajate vajadustest lähtuvalt sujuvalt lülituda erinevate suhtlusrežiimide vahel. Kasutaja võib alustada tekstiküsimusega printeri parandamise kohta, saata veateatest foto, saada asjakohaseid nuppe esile tõstva diagrammi ja seejärel lülituda hääljuhistele, kui tema käed on remondiga hõivatud.
See multimodaalne lähenemine ei kujuta endast mitte ainult tehnilist edusamme, vaid ka põhjapanevat nihet loomulikuma inimese ja arvuti suhtluse poole – kasutajatega kohtumine mis tahes suhtlusrežiimis, mis nende praeguse konteksti ja vajaduste jaoks kõige paremini sobib.
Retrieval-Augmented Generation: AI maandamine faktides
Vaatamata muljetavaldavatele võimalustele on suurtel keelemudelitel omased piirangud. Nad võivad teavet "hallutsineerida", kinnitades enesekindlalt usutavalt kõlavaid, kuid ebaõigeid fakte. Nende teadmised piirduvad nendega, mis olid nende koolitusandmetes, luues teadmiste piirkuupäeva. Ja neil puudub juurdepääs reaalajas teabele või spetsiaalsetele andmebaasidele, välja arvatud juhul, kui see on spetsiaalselt loodud.
Retrieval-Augmented Generation (RAG) oli nende väljakutsete lahendus. Selle asemel, et toetuda ainult koolituse käigus õpitud parameetritele, ühendavad RAG-süsteemid keelemudelite generatiivsed võimed otsingumehhanismidega, millel on juurdepääs välistele teadmisteallikatele.
Tüüpiline RAG-i arhitektuur töötab järgmiselt:
Süsteem saab kasutaja päringu
See otsib päringuga seotud teavet asjakohastest teadmistebaasidest
See edastab keelemudelile nii päringu kui ka hangitud teabe
Mudel genereerib vastuse, mis põhineb leitud faktidel
Sellel lähenemisviisil on mitmeid eeliseid:
Täpsemad ja faktipõhised vastused kontrollitud teabe loomisel
Võimalus pääseda juurde ajakohasele teabele väljaspool mudeli treeningu piirmäära
Spetsiaalsed teadmised domeenipõhistest allikatest, nagu ettevõtte dokumentatsioon
Läbipaistvus ja omistamine teabeallikatele viidates
Vestlust tehisintellekti rakendavate ettevõtete jaoks on RAG osutunud klienditeenindusrakenduste jaoks eriti väärtuslikuks. Näiteks pangavestlusbot pääseb juurde uusimatele poliitikadokumentidele, kontoteabele ja tehingukirjetele, et pakkuda täpseid ja isikupärastatud vastuseid, mis oleks iseseisva keelemudeli korral võimatu.
RAG-süsteemide areng jätkub otsingutäpsuse paranemise, otsitud teabe ja loodud tekstiga integreerimise keerukamate meetodite ning erinevate teabeallikate usaldusväärsuse hindamise paremate mehhanismidega.
Retrieval-Augmented Generation (RAG) oli nende väljakutsete lahendus. Selle asemel, et toetuda ainult koolituse käigus õpitud parameetritele, ühendavad RAG-süsteemid keelemudelite generatiivsed võimed otsingumehhanismidega, millel on juurdepääs välistele teadmisteallikatele.
Tüüpiline RAG-i arhitektuur töötab järgmiselt:
Süsteem saab kasutaja päringu
See otsib päringuga seotud teavet asjakohastest teadmistebaasidest
See edastab keelemudelile nii päringu kui ka hangitud teabe
Mudel genereerib vastuse, mis põhineb leitud faktidel
Sellel lähenemisviisil on mitmeid eeliseid:
Täpsemad ja faktipõhised vastused kontrollitud teabe loomisel
Võimalus pääseda juurde ajakohasele teabele väljaspool mudeli treeningu piirmäära
Spetsiaalsed teadmised domeenipõhistest allikatest, nagu ettevõtte dokumentatsioon
Läbipaistvus ja omistamine teabeallikatele viidates
Vestlust tehisintellekti rakendavate ettevõtete jaoks on RAG osutunud klienditeenindusrakenduste jaoks eriti väärtuslikuks. Näiteks pangavestlusbot pääseb juurde uusimatele poliitikadokumentidele, kontoteabele ja tehingukirjetele, et pakkuda täpseid ja isikupärastatud vastuseid, mis oleks iseseisva keelemudeli korral võimatu.
RAG-süsteemide areng jätkub otsingutäpsuse paranemise, otsitud teabe ja loodud tekstiga integreerimise keerukamate meetodite ning erinevate teabeallikate usaldusväärsuse hindamise paremate mehhanismidega.
Inimese ja tehisintellekti koostöömudel: õige tasakaalu leidmine
Kuna vestluse AI võimalused on laienenud, on inimeste ja tehisintellektisüsteemide vahelised suhted arenenud. Varased vestlusrobotid olid selgelt positsioneeritud tööriistadena – piiratud ulatusega ja ilmselgelt mitteinimlikud. Kaasaegsed süsteemid hägustavad neid jooni, tekitades uusi küsimusi selle kohta, kuidas kavandada tõhusat inimese ja tehisintellekti koostööd.
Tänapäeva kõige edukamad rakendused järgivad koostöömudelit, kus:
AI käsitleb rutiinseid korduvaid päringuid, mis ei nõua inimese otsustusvõimet
Inimesed keskenduvad keerulistele juhtumitele, mis nõuavad empaatiat, eetilist arutlust või loomingulist probleemide lahendamist
Süsteem teab oma piiranguid ja levib vajaduse korral sujuvalt inimagentideni
Üleminek tehisintellekti ja inimtoe vahel on kasutaja jaoks sujuv
Inimagentidel on tehisintellektiga peetud vestluse ajaloo täielik kontekst
AI jätkab inimeste sekkumisest õppimist, laiendades järk-järgult oma võimalusi
See lähenemine tunnistab, et vestluse tehisintellekt ei peaks olema suunatud inimestevahelise suhtluse täielikule asendamisele, vaid pigem seda täiendama – käsitledes mahukaid, otsekoheseid päringuid, mis kulutavad inimagentide aega, tagades samas, et keerukad probleemid jõuavad õigete inimeste teadmisteni.
Selle mudeli rakendamine on tööstusharudes erinev. Tervishoius võivad tehisintellekti vestlusrobotid tegeleda kohtumiste planeerimise ja põhisümptomite sõeluuringuga, tagades samas, et arstiabi annavad kvalifitseeritud spetsialistid. Õigusteenustes võib tehisintellekt aidata dokumente koostada ja uurida, jättes tõlgendamise ja strateegia advokaatide hooleks. Klienditeeninduses saab AI lahendada levinud probleeme, suunates samal ajal keerukad probleemid spetsialiseeritud agentidele.
Kuna tehisintellekti võimalused arenevad edasi, nihkub piir inimeste kaasamist nõudva ja automatiseeritava vahel, kuid põhiprintsiip jääb alles: tõhus vestluspõhine tehisintellekt peaks pigem suurendama inimeste võimeid, mitte neid lihtsalt asendama.
Tänapäeva kõige edukamad rakendused järgivad koostöömudelit, kus:
AI käsitleb rutiinseid korduvaid päringuid, mis ei nõua inimese otsustusvõimet
Inimesed keskenduvad keerulistele juhtumitele, mis nõuavad empaatiat, eetilist arutlust või loomingulist probleemide lahendamist
Süsteem teab oma piiranguid ja levib vajaduse korral sujuvalt inimagentideni
Üleminek tehisintellekti ja inimtoe vahel on kasutaja jaoks sujuv
Inimagentidel on tehisintellektiga peetud vestluse ajaloo täielik kontekst
AI jätkab inimeste sekkumisest õppimist, laiendades järk-järgult oma võimalusi
See lähenemine tunnistab, et vestluse tehisintellekt ei peaks olema suunatud inimestevahelise suhtluse täielikule asendamisele, vaid pigem seda täiendama – käsitledes mahukaid, otsekoheseid päringuid, mis kulutavad inimagentide aega, tagades samas, et keerukad probleemid jõuavad õigete inimeste teadmisteni.
Selle mudeli rakendamine on tööstusharudes erinev. Tervishoius võivad tehisintellekti vestlusrobotid tegeleda kohtumiste planeerimise ja põhisümptomite sõeluuringuga, tagades samas, et arstiabi annavad kvalifitseeritud spetsialistid. Õigusteenustes võib tehisintellekt aidata dokumente koostada ja uurida, jättes tõlgendamise ja strateegia advokaatide hooleks. Klienditeeninduses saab AI lahendada levinud probleeme, suunates samal ajal keerukad probleemid spetsialiseeritud agentidele.
Kuna tehisintellekti võimalused arenevad edasi, nihkub piir inimeste kaasamist nõudva ja automatiseeritava vahel, kuid põhiprintsiip jääb alles: tõhus vestluspõhine tehisintellekt peaks pigem suurendama inimeste võimeid, mitte neid lihtsalt asendama.
Tulevikumaastik: kuhu suundub vestluslik AI
Kui vaatame horisonti, kujundavad mitmed esilekerkivad suundumused vestluspõhise AI tulevikku. Need arengud ei luba mitte ainult järkjärgulisi täiustusi, vaid ka potentsiaalselt transformatiivseid muutusi selles, kuidas me tehnoloogiaga suhtleme.
Isikupärastamine ulatuslikult: tulevased süsteemid kohandavad oma vastuseid üha enam mitte ainult vahetule kontekstile, vaid iga kasutaja suhtlusstiilile, eelistustele, teadmiste tasemele ja suhete ajaloole. See isikupärastamine muudab suhtluse loomulikumaks ja asjakohasemaks, kuigi tõstatab olulisi küsimusi privaatsuse ja andmekasutuse kohta.
Emotsionaalne intelligentsus: kuigi tänapäeva süsteemid suudavad tuvastada põhitunde, arendavad tulevased vestluse tehisintellektid keerukamat emotsionaalset intelligentsust – tunnevad ära peened emotsionaalsed seisundid, reageerivad asjakohaselt stressile või frustratsioonile ning kohandavad vastavalt oma tooni ja lähenemist. See võimalus on eriti väärtuslik klienditeeninduse, tervishoiu ja hariduse rakendustes.
Ennetav abi: selle asemel, et oodata selgesõnalisi päringuid, prognoosivad järgmise põlvkonna vestlussüsteemid vajadusi konteksti, kasutajate ajaloo ja keskkonnasignaalide põhjal. Süsteem võib märgata, et plaanite mitu kohtumist võõras linnas, ja pakub ennetavalt transpordivõimalusi või ilmaennustusi.
Sujuv mitmeliigiline integreerimine: tulevased süsteemid ei piirdu lihtsalt erinevate viiside toetamise ja nende sujuva integreerimisega. Vestlus võib kulgeda loomulikult teksti, hääle, piltide ja interaktiivsete elementide vahel, valides iga teabe jaoks õige viisi, ilma et oleks vaja selget kasutaja valikut.
Spetsialiseerunud domeenieksperdid: kuigi üldotstarbelised assistendid täiustuvad, näeme ka kõrgelt spetsialiseerunud vestluse AI esilekerkimist, millel on sügavad teadmised konkreetsetes valdkondades – juristid, kes mõistavad kohtupraktikat ja pretsedenti, meditsiinisüsteemid, kellel on põhjalikud teadmised ravimite koostoimete ja raviprotokollide kohta, või finantsnõustajad, kes on kursis maksuseadustiku ja investeerimisstrateegiatega.
Tõeliselt pidev õppimine: tulevased süsteemid liiguvad peale perioodilise ümberõppe pidevale suhtlusest õppimisele, muutudes aja jooksul abivalmimaks ja isikupärasemaks, säilitades samal ajal asjakohased privaatsuskaitsed.
Vaatamata nendele põnevatele võimalustele on väljakutseid endiselt. Privaatsusprobleemid, eelarvamuste leevendamine, asjakohane läbipaistvus ja inimliku järelevalve õige taseme loomine on pidevad probleemid, mis kujundavad nii tehnoloogiat kui ka selle reguleerimist. Kõige edukamad on need rakendused, mis tegelevad nende väljakutsetega läbimõeldult, pakkudes kasutajatele tõelist väärtust.
Selge on see, et vestluspõhine AI on liikunud nišitehnoloogiast peavoolu liidese paradigmaks, mis hakkab üha enam vahendama meie suhtlust digitaalsüsteemidega. Evolutsiooniline tee ELIZA lihtsast mustrite sobitamisest tänapäevaste keerukate keelemudeliteni on üks olulisemaid edusamme inimese ja arvuti suhtluses – ja teekond pole veel kaugeltki lõppenud.
Isikupärastamine ulatuslikult: tulevased süsteemid kohandavad oma vastuseid üha enam mitte ainult vahetule kontekstile, vaid iga kasutaja suhtlusstiilile, eelistustele, teadmiste tasemele ja suhete ajaloole. See isikupärastamine muudab suhtluse loomulikumaks ja asjakohasemaks, kuigi tõstatab olulisi küsimusi privaatsuse ja andmekasutuse kohta.
Emotsionaalne intelligentsus: kuigi tänapäeva süsteemid suudavad tuvastada põhitunde, arendavad tulevased vestluse tehisintellektid keerukamat emotsionaalset intelligentsust – tunnevad ära peened emotsionaalsed seisundid, reageerivad asjakohaselt stressile või frustratsioonile ning kohandavad vastavalt oma tooni ja lähenemist. See võimalus on eriti väärtuslik klienditeeninduse, tervishoiu ja hariduse rakendustes.
Ennetav abi: selle asemel, et oodata selgesõnalisi päringuid, prognoosivad järgmise põlvkonna vestlussüsteemid vajadusi konteksti, kasutajate ajaloo ja keskkonnasignaalide põhjal. Süsteem võib märgata, et plaanite mitu kohtumist võõras linnas, ja pakub ennetavalt transpordivõimalusi või ilmaennustusi.
Sujuv mitmeliigiline integreerimine: tulevased süsteemid ei piirdu lihtsalt erinevate viiside toetamise ja nende sujuva integreerimisega. Vestlus võib kulgeda loomulikult teksti, hääle, piltide ja interaktiivsete elementide vahel, valides iga teabe jaoks õige viisi, ilma et oleks vaja selget kasutaja valikut.
Spetsialiseerunud domeenieksperdid: kuigi üldotstarbelised assistendid täiustuvad, näeme ka kõrgelt spetsialiseerunud vestluse AI esilekerkimist, millel on sügavad teadmised konkreetsetes valdkondades – juristid, kes mõistavad kohtupraktikat ja pretsedenti, meditsiinisüsteemid, kellel on põhjalikud teadmised ravimite koostoimete ja raviprotokollide kohta, või finantsnõustajad, kes on kursis maksuseadustiku ja investeerimisstrateegiatega.
Tõeliselt pidev õppimine: tulevased süsteemid liiguvad peale perioodilise ümberõppe pidevale suhtlusest õppimisele, muutudes aja jooksul abivalmimaks ja isikupärasemaks, säilitades samal ajal asjakohased privaatsuskaitsed.
Vaatamata nendele põnevatele võimalustele on väljakutseid endiselt. Privaatsusprobleemid, eelarvamuste leevendamine, asjakohane läbipaistvus ja inimliku järelevalve õige taseme loomine on pidevad probleemid, mis kujundavad nii tehnoloogiat kui ka selle reguleerimist. Kõige edukamad on need rakendused, mis tegelevad nende väljakutsetega läbimõeldult, pakkudes kasutajatele tõelist väärtust.
Selge on see, et vestluspõhine AI on liikunud nišitehnoloogiast peavoolu liidese paradigmaks, mis hakkab üha enam vahendama meie suhtlust digitaalsüsteemidega. Evolutsiooniline tee ELIZA lihtsast mustrite sobitamisest tänapäevaste keerukate keelemudeliteni on üks olulisemaid edusamme inimese ja arvuti suhtluses – ja teekond pole veel kaugeltki lõppenud.





